category-group: dbag
layer(s): 3, 5 header file(s): z_dbag.h, z_dbag_array.h, z_dbag_list.h, z_dbag_recurs.h, z_dbag_matrix.h classes in this group: dbag_o, simple_dbag_o, list_dbag_o, array_dbag_o, rec_dbag_o, matrix_dbag_o, HTI_dbag_o function groups:
layer 05 functions group description.
A databag is a container for storing data in text format. Outside of storing text data, it has no behavior in itself. It is oriented towards text - non-text data cannot be stored in a databag. The contents of a databag can be mapped onto a string; the resultant text contains the data formatted with tokens that represent how the data is stored in a databag. When a string is given to a databag, it will be automatically parsed. using a databag for managing your data is a surrogate for creating data structures in programs. It provides a simple, typeless framework for managing data. Whatever data goes into a class and can be represented by a strings can also go into a databag, so you should be able to use a databag wherever you would use a class. There are a set of classes for databags. Each class represents a type of container. The storage types available are: basic name-value pairs ("simple"); list; array; table ("matrix"); and recursive:
- Simple databag: this is for a simple datum. The properties of the datum relevant to a simple databag are its name and value. Both properties are stored as strings in a databag. The text format of this databag is simply "NAME VALUE". Note that all tokens are separated by white space; see the section "Data bag Text Format" for more on this. . In text form, a basic databag has a name followed by a set of parenthesis: "MyData ()". .
- Array (aka List ) databag: use this for a set of values. An array databag has a name, and a set of string tokens, which are contained within angle brackets: "NAME < value_0 value_1 .. value_n >" .
- Matrix : holds a set of Array databags. Can be treated as a [2-dimensional] matrix of data. .
- Recursive : This is an important type of databag,
as it allows nesting of databags. This opens up the ability
to store complex data structures in a string. Its string
representation is like so:
"NAME (
)"
Parenthesis is used to indicate that there is another databag within the recursive databag. Text can be put inside the parenthesis; this represents a databag within a databag. We can organize data in a hierarchical fashion.
rec_dbag_o bag rx ("SampleData (Owner Edmond Item 512)");
string_o s = rx.get ("Owner"); // 's' contains "Edmond"
Data bag class hierarchy is straightforward:
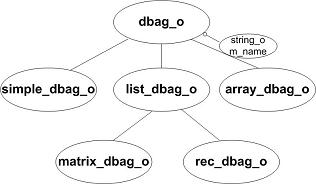 In simplest form, a databag provides a way to record 2 fundamental
properties of a datum: its name and value. A third fundamental property
of data in a computer language is type. For databags, this is always a
text string. This excludes non-text data from databags. Such data may
be included if there is a way to convert its type to text (strings, or
character arrays) and back. Note that such conversion filters might not
be able to do exact translations. A notable case in point is that of
real numbers stored as floating-point variables.
A databag can be written out as a string. Conversely, a string can be
given to a databag, which would parse the string and populate itself
from the string's contents. The databag can then be used to retrieve
data. Since a databag can decompose a string to populate itself, it
has a parser. Actually, each type of databag has its own parser. When
a databag is given a string, it expects the string to be of correct
format for its type.
Data bags are oriented towards small chunks of data. It is recommended
to use some other packetization technique to hold large binary data,
if efficiency is a concern.
Modified data.
When data is modified, the fact that it has changed becomes a property
of the data. This is the fundamental issue regarding copy-on-write,
and is evident in text editors, where if a file has been modified,
even by only 1 character, the entire file needs to be re-written to
the file system. When a databag is modified, this fact is recorded
in its "is-modified" flag. A question arises: when a databag is copied,
should this property propagate to the recipient databag? Consider:
In simplest form, a databag provides a way to record 2 fundamental
properties of a datum: its name and value. A third fundamental property
of data in a computer language is type. For databags, this is always a
text string. This excludes non-text data from databags. Such data may
be included if there is a way to convert its type to text (strings, or
character arrays) and back. Note that such conversion filters might not
be able to do exact translations. A notable case in point is that of
real numbers stored as floating-point variables.
A databag can be written out as a string. Conversely, a string can be
given to a databag, which would parse the string and populate itself
from the string's contents. The databag can then be used to retrieve
data. Since a databag can decompose a string to populate itself, it
has a parser. Actually, each type of databag has its own parser. When
a databag is given a string, it expects the string to be of correct
format for its type.
Data bags are oriented towards small chunks of data. It is recommended
to use some other packetization technique to hold large binary data,
if efficiency is a concern.
Modified data.
When data is modified, the fact that it has changed becomes a property
of the data. This is the fundamental issue regarding copy-on-write,
and is evident in text editors, where if a file has been modified,
even by only 1 character, the entire file needs to be re-written to
the file system. When a databag is modified, this fact is recorded
in its "is-modified" flag. A question arises: when a databag is copied,
should this property propagate to the recipient databag? Consider:
void main()
{
rec_dbag_o a, b;
b = "FooBar (item beverage type beer)"; // b is modified
a = b; // is a modified?
}
The answer is not obvious. Prior to 2013, the copy operation cleared
out the "is-modified" flag. However, this adversely affected the
orthodox class, which does a lot of databag copying prior to an
orthodox object being saved to a database. A new feature has been
added - the ability to specify whether or not this property propagates:
void main()
{
rec_dbag_o a, b;
b = "FooBar (item beverage type beer)"; // b is modified
dbag_o::set_deepmod(); // turn ON mod-on-copy
a = b; // a IS modified
if (dbag_o::isset_mod_oncopy()) // check: mod-on-copy?
dbag_o::turnoff_deepmod(); // aka unset_deepmod()
a = b; // a is NOT modified
}
Unfortunately, this setting controls all databag copy operations
in the program's space at any given time. Thus, if in a multi-threaded
application thread A wants is-modified to propagate on copy operations,
whereas thread B does not, they have to agree on a single global
setting at any given time.
When orthodox_o::store_add() is called, the "deep-modify"
mode is set on, and when the function exits, the previous state
is restored. This can present problems in complex multi-threaded
applications.
Finally, sometimes you need to dispense with all these rules, and do
a wholesale over-ride of the "is-modified" flag settings in a databag.
You can set every sub-databag's flag on or off with mod_setall()
and mod_clearall() (or mod_setall(FALSE)). These
functions will do a recursive descent, if possible, turning on or
off the flag of each and every databag encountered.
usage. The name of a data item is stored as the value of the top-level class (of type "string_o). The value of the data is stored in a string, contained in the class simple databag. Two primary operations are:
- get(): gets the name or value of a databag
- put(): sets a new value of a databag
- getting or putting a databag
- getting or putting a [string] value
get (string_o path)The first step in using a databag is to structure the data. This involves constructing a representation of the layout of the data in text format. Consider here an example of describing an airplane, in a databag:
get the value of the databag found by "path". If that databag is of type "simple", its value is returned; otherwise, it is a more complex [container] databag, and the name is returned operator string_o () & name()
these 2 member functions are equivalent to get("") put (string_o path, string_o value, boolean domod = FALSE)
replaces the value of the simple databag found by "path" with "value". If "domod" is TRUE, the databag will be marked as having been modified. If this value is FALSE (the default), the bag will be set to "is modified" state only if the value supplied is different from any prior value. get_dbag (string_o path)
returns a reference to the databag (cast as a simple_dbag_o &) put_dbag (string_o path, simple_dbag_o s)
puts the input parameter databag ("s") into location "path" set_name (string_o new_name)
re-sets the name of the databag (to "new_name")
- Identify the data. An airplane has 2 wings, 1 or more engines, a pilot, a set of passengers, and a set of chairs for the passengers, usually laid out in a matrix.
- Structure the data. Determine what the scope of a single data bag is, and what is to go into it.
- Construct a text string as an example. Apply the string to a [recursive] databag.
const string_o my_folks =
"table_1 \n\
( \n\
< Fname Lname Sex Age Height > \n\
< Rodney Dangerfield M 101 72> \n\
< Lavella Jordan F 33 68> \n\
< Rosey "O'Donnell" F 33 68> \n\
)";
// ...
rec_dbag_o bag_o_info (my_folks);
When writing the data in a string, you don't need to put double-quotes
around the tokens unless they have 'non-word characters' inside -
alphanumeric characters (and underscores). Otherwise, embed the
string in double-quotes. Surround the tokens with white-space, to
distinguish them. The special tokens used to represent data storage
information include parenthesis - "(" & ")" for recursive and
list databags, and "<" & ">" for array databags. "COLUMNS"
is a reserved word that starts a table databag.
Here's an example (also found in the simple databag object):
textstring_o ts = "my,oh,my-what-a-complex:name";
ts.wrap_quotes(); // puts double-quotes around "my,..
simple_dbag_o sbag(ts); // sbag's "name" is "my,oh,my"..
sbag.put ("", "a_value"); // value is a simple "word"; no quotes
Data bag names are case-sensitive. Carriage returns and new-lines are
not treated as white-space (a flaw?).
comparing databags
A databag can be "equal to" (or not equal to) another databag when:
- The two databags have the same type.
- The two databags have the same name.
- Each subcomonent databag have the same "size". As to what constitutes size, this is defined by the defabag type. For the matrix sub-class, this would be the number of columns. For lists, the number of elements. For the "simple" sub-class, this is always 1.
- Each sub-databag item (or element, in the case of arrays and matrices) within the databag "matches". For elements, a match is a simple string comparison. For sub-databags, it depends on the type - eg, all the other rules must apply.
Every databag can be reset: this is a destructive action that wipes out everything in a databag, including its name. Although most databags contain many other objects internally, there is no need to worry about memory management: memory for all objects internal to any given databag will be automatically de-allocated. An alternative, slightly less destructive action is to call empty_out(), which will wipe out internal data but leave the name of the [outer] databag intact. The behaviour of this function changes from databag type to type, wo what gets discarded varies according to the rules of the class type. This member function reflects the highly polymorphic nature of databags - the meaning of a given operation (such as this one, or adding to a bag) is subject to interpretation by the class. The rules for emptying out are:
- simple databags: The value will be set to empty ("").
- array databags: the names in the array will be removed.
- list databags: each sub-databag in the list is removed - the list databag will be devoid of any members in its list. Basically the operation is identical to that of recursive databags.
- matrix databags: data rows will be removed. The header will be left intact (preserving the schema).
- recursive databags: the bag will be completely emptied. It will have nothing inside at all.
The array databag is a list of strings. They operate in 2 modes: table-oriented and not. In "table mode", the name of the databag is not involved in the parsing or printing of the corresponding string representation of an array databag:
// "normal" mode: array_dbag_o a = "mylist < 38 44 0 19 17 50 2050 >"; // "table" mode: array_dbag_o a2; a2.set_tablemode(); a2 = "<19 89 98 66 69 70>";The reason for table mode is apparent in the table databag. Without the array databag being able to run in this mode, each row would require a name prepended to its list of values:
table_o
(
COLUMNS < Fname Lname Sex Age Height >
< Rodney Dangerfield M 101 72> \n\
row1 < Lavella Jordan F 33 68>
)
This is an undesirable style of printing out the data; it would be
more aesthetic to drop "row0" & "row1":
table_1
(
< Fname Lname Sex Age Height >
< Lavella Jordan F 33 68>
)
This syntax is still lacking; we need a token for the recursive data
bag to distinguish the fact that a table databag is to be parsed.
The old style relied on the opening parenthesis (the first "(" after
"table_1"). The new syntax is:
TopLevelName
[
< v00 v01 .. v0n >
..
< vm0 vm1 .. vmn >
]
the token "[" tells the recursive databag string parser to start a
table databag parse (a previous implementation stored each row as
an array databag inside a list databag. It was found that a list
databag was returned when a table databag was expected).
Error messages are displayed to stderr. There are 3 functions
in the top-level databag class (dbag_o) to support this:
is_announcing_errors() -- tell if error messages are being printed announce_errors() -- turn on error message logging dont_announce_errors() -- turn off error message loggingnote.
Databags may seem tediously complex at first. But once you start using them, and becoming familiar with their behaviour, you will probably soon find them to be indispensible, providing the optimal data storage solution for many software problems. The option to be able to force a databag doing a put() operation to record its state as "is modified" is a very new feature (as of 2013). It became apparent that application control was necessary (or any framework software that uses databags), so that the default behaviour can be over-ridden. This is used by the orthodox_o class when saving a record to the database. If a record's field in the database is a NULL value, and the corresponding object is retrieved, the object's string value for that field could be an empty string. If a value of the field is to be an empty string ("") after a save (orthodox_o::store_save()), the application may need to force the object's string to an "is modified" state (The orthodox object saves only fields that have been modified). The original design of empty_out() was to have an optional [boolean] argument, "hard" - if a "hard" emptying-out is done, this would remove more. The flag would exist mainly for recursive databags, which would completely remove the guts of the bag, leaving an empty shell. In the "soft" case (the default), if a sub-bag of recursive type is encountered, it remains intact. Thus, given a series of matroska-like recursive databags, those bags will remain even after a call to empty_out(). This scheme proved too unwieldy (compliated and confusing), and so was abandoned.